If running as a Docker image, make sure to port-forward the metrics endpoint
port. For instance, to forward port 9090 on the local port 80, add the
following flag to your
docker run command: -p 9090:80Metrics
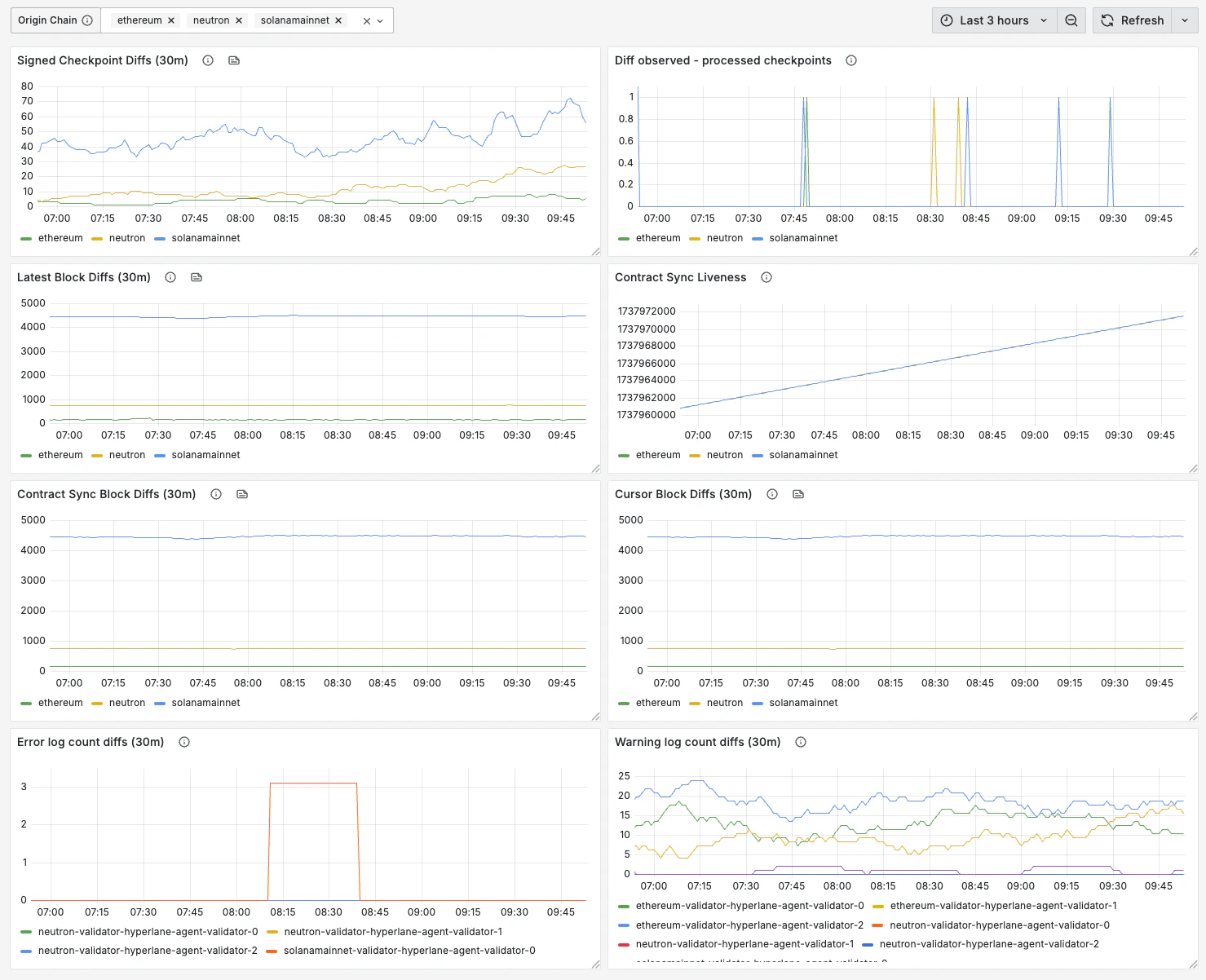
The dashboard template includes the following metrics.Charts
The dashboard template includes the following charts.Alerts
All the metrics above can be combined to create alerts that minimize false positives. Some example critical alerts:- the
hyperlane_latest_checkpointstopped increasing, but thehyperlane_block_heightis still increasing, anderrorandwarnlog counts have also been increasing, over the last 6 hours hyperlane_block_heighthas not increased in the last 30 minutes